
Hinweis: Die IT-Power Services weist darauf hin, dass dieser Blogbeitrag zu reinen Informationszwecken erstellt wurde und keinerlei Meinung unseres Unternehmens oder Einzelpersonen darstellt, wenn nicht explizit angeführt. Diese Informationen wurden nach bestem Wissen und Gewissen zusammengestellt, erheben aber keinen Anspruch auf Vollständigkeit.
Was ist Künstliche Intelligenz? Der Begriff künstliche Intelligenz ist mittlerweile wohl jedem bekannt – das Konzept ist aber prinzipiell nichts Neues: Der Begriff wurde bereits in den 50er Jahren eingeführt und Geoffrey Hinton, der “Godfather” der modernen KI, beschäftigt sich seit den 70er Jahren damit. Aber die Entwicklung in den letzten Jahren ist enorm. In dieser Blogserie beleuchten wir was dahinter steckt, worin Experten Risiken sehen und wie auch Mittelstandsunternehmen KI nutzen können.
Was ist Künstliche Intelligenz?
Lt. Duden ist die Definition von Intelligenz wie folgt: Fähigkeit (des Menschen), abstrakt und vernünftig zu denken und daraus zweckvolles Handeln abzuleiten. Gina Lückenkemper erklärt das mit Humor aus ihrer sportlichen Sicht im Video von MAITHINK X:
Der Begriff “künstliche Intelligenz” (KI, oder im englischen: AI für Artificial Intelligence) wurde seit seiner Einführung vor gut 60 Jahren für eine Reihe unterschiedlicher technischer Konzepte verwendet, die jeweils eine gewisse Zeit “in Mode” waren. Die Methode, die für die Durchbrüche der letzten Jahre gesorgt hat ist Machine Learning (ML) mithilfe von künstlichen neuronalen Netzen (KNN, bzw. ANN im Englischen). Weil künstliche neuronale Netze aus “Schichten” bestehen, hat sich auch der Begriff “Deep Learning” eingebürgert. Mittlerweile wird “KI“ oft als Synonym für diese Technik verwendet.
Wie funktioniert Machine Learning?
Damit maschinelles Lernen funktioniert, muss ein “Modell” mittles eines Lern-Algorithmuses auf vorhandenen Daten trainiert werden.
Die “mächtigsten” Modelle sind “tiefe” künstliche neuronale Netze mit vielen Schichten, die so etwas wie ein „künstliches Hirn“ darstellen. Die dafür verwendeten Lern-Algorithmen sind vom menschlichen Lernen inspiriert. Diese sind in der Lage große Mengen an (strukturierten und auch unstrukturierten) Daten besonders gut auszuwerten und darin Muster zu finden.
Der Computer wird also mit vielen (oft Millionen) Trainings- bzw. Beispieldatensätzen „gefüttert“. Für ein Modell, das Objekte in Bildern erkennen soll sind das die Beispielbilder selbst sowie die Namen und Positionen der zu identifizierenden Objekte zu jedem Bild. Der Algorithmus durchsucht nun den Input nach Mustern, Zusammenhängen, verborgenen Strukturen und Abhängigkeiten, die verwendet werden können, um die vorgegebenen Objekte zu erkennen. Diesen Vorgang nennt man „Modelltraining“.
Nach dem abgeschlossenen Lernprozess wird das trainierte Modell nun mit ihm unbekannten Daten (in unserem Beispiel also neue Bilder, bei denen noch keine Objekte voridentifiziert sind) konfrontiert. Nun kann das Modell die erlernten Muster und Zusammenhänge wiederverwenden, um die gestellte Aufgabe (Identifikation und Verortung der Objekte) zu erfüllen.
Eine gute Demonstration dazu finden Sie auf dieser Website oder auch im Video MAITHINK X (und auch eine einfache Erklärung, warum KI auch „Fehler“ macht).
Die Diskussionspunkte
Dennis Pamlin und KI-Forscher Stuart Armstrong haben am Future of Humanity Institute der Oxford Universität einen Bericht veröffentlicht, „der KI zu den 12 globalen Bedrohungen mit potentiell unbegrenzten und unwiderruflichen Folgen zählt“.
Stephen Hawking, der zwar kein KI-Spezialist war, aber als eines der größten Genies des letzten Jahrhunderts beachtenswerte Beiträge zu vielen Zukunftsthemen lieferte, ging sogar einen Schritt weiter:“ Die primitiven Formen von KI, die wir bereits haben, erwiesen sich als sehr nützlich. Aber ich denke, die Entwicklung von vollwertiger KI, könnte das Ende der Menschheit bedeuten.“
Aber warum?
Fake News und Bilder
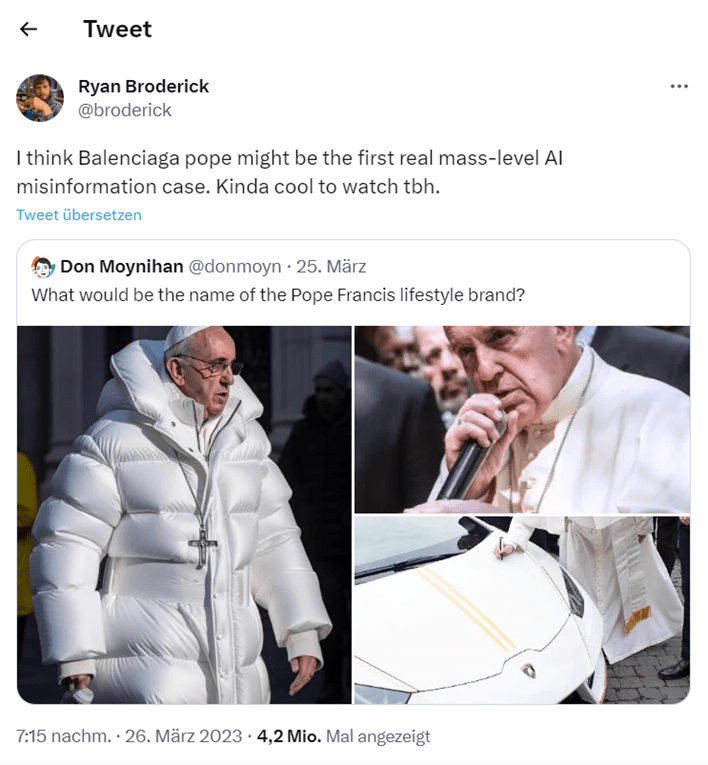
Sie haben sicherlich die Welle an Papst-, Macron-, Trump- und anderen Promibildern mitbekommen, die in letzter Zeit mittels bilderzeugenden KI-Modellen erstellt wurde und in den Medien landeten. Pablo Xavier aus Chicago hatte kürzlich seinen Bruder verloren. Mit KI-generierten Bildern seines Bruders hat er seine Trauer verarbeitet. Eines Tages wollte er einfach was Lustiges machen und erschuf das Papstbild. In Interviews nach dem Aufruhr sagte er selbst „es habe ihn beängstigt, dass die Leute es für real hielten ohne es zu hinterfragen und dass er sich benutzt fühlte um die Ausgaben der Kirche zu kritisieren“. Quelle: BuzzFeedNews
Newsletter-Autor des „Garbage Day“, Ryan Broderick, nannte es „den ersten echten KI-Fehlinformationsfall auf Massenebene“.
Luxus der Zeit fehlt
Es gibt ein natürliches Tempo für menschliche Überlegungen. Vieles geht kaputt, wenn uns der Luxus der Zeit verwehrt wird. Aber das ist die Art von Moment, in dem wir uns meiner Meinung nach jetzt befinden. Wir können uns nicht den Luxus leisten, so langsam zu reagieren, zumindest nicht, wenn sich die Technologie so schnell weiterentwickelt.“
https://www.nytimes.com/2023/03/12/opinion/chatbots-artificial-intelligence-future-weirdness.html
So schrieb Journalist Ezra Klein am 12. März 2023 in seiner Kolumne
Auf deutsch: wir sind zu langsam – oder die Technik zu schnell. Die großen Technologieunternehmen wollen natürlich aus wirtschaftlichen Gründen den Fortschritt beschleunigen. Das Bild des „Designer-Papstes“ ist hier gewissermaßen der Moment einer kulturellen Phasenveschiebung, was unser technisches Verständnis und die nicht nachvollziehbaren Fähigkeiten der KI anbelangt. An unserer Überraschung und dem falschen Umgang mit dem Foto, also dass wir es für echt halten und verbreiten, merken wir, dass KI und Gesellschaft schon in verschiedenen Geschwindigkeiten operieren.
Aus Spaß wird ernst
Über den Papst im modischen Designermantel kann man vielleicht noch schmunzeln. Gefährlich wird es, wenn KI-generierte Bilder für Feindbildschaffung benutzt wird. So geschehen im März 2021 als ein deutscher Politiker einen Instagram-Post veröffentlichte, um gegen Flüchtlinge zu hetzen. Darauf zu sehen war eine Gruppe migrantisch aussehender Männer mit weit aufgerissenen Mündern und aggressiver Mimik. Auch wenn man das Bild als KI-generiertes Bild erkennen kann, (5 Finger links unten im Bild ohne Daumen) darf die unterschwellige Wirkung der Bilder nicht unterschätzt werden. Darin wird ein großes Risiko durch Experten gesehen. Der Akademiker Francois Fleuret erinnert sich an die Rede eines Vortragenden während eines Treffens zu Falschinformationen in den Medien: „Er sagte, dass es zwischen der Erfindung der Fotografie und heute eine gesegnete Zeit gegeben habe. Die Fotografie vermittelte objektive Informationen über die Realität. Bis zu einem gewissen Grad.“
Wenn aber KI-generierte Bilder beliebiger Personen bei beliebigen Handlungen täuschend echt und mit vernachlässigbarem Aufwand erstellt werden können, müssen wir unser „Grundvertrauen“, das wir intuitiv in Fotografien haben wohl aufgeben. (siehe narrative Manipulation)
Urheberrechte der Beispiel- und Trainingsdaten
Ein weiteres kontroversiell diskutiertes Thema sind Urheberrechte an Trainingsdaten: Die Beispieldaten die für das Modelltraining herangezogen werden, stammen (meistens) aus dem Internet. Diese Informationen sind oft urheberrechtlich geschützt. Was das für die mit solchen Daten trainierten Modellen und deren Output rechtlich bedeutet, muss erst geklärt werden.
Kunstbranche in Aufruhr
In San Francisco läuft eine Klage der Anwälte Matthew Butterick zusammen mit der Anwaltskanzlei Joseph Saveri gegen Microsoft, GitHub und OpenAI, weil sie „Copilot“, einen Codegenerator, erstellt haben, der auf vorhandenen Codes trainiert wurde, die online verfügbar waren. Dies geschah allerdings ohne Erlaubnis der Ingenieure, die diese Codes geschrieben hatten (mehr dazu auf der Website).
Kelly McKernan, ein Künstler aus Nashville erstellt Aquarell- und Acryl-Gouache Originalillustrationen für Bücher, Comics und Spiele. Eines Tages fand er heraus, dass einige seiner Kunstwerke zum Trainieren von „Stable Diffusion“, einer bildgenerierenden KI, verwendet wurden. Ihm wurde klar, dass jeder der dieses kostenlose KI-Modell verwendet, Kunstwerke in seinem Stil erstellen kann. Dazu hatte er nie seine Einwilligung gegeben.
Karla Ortiz, die Bleistiftporträts erstellt, und Sarah Andersen, die sich auf schwarz-weiße Webcomics spezialisiert hat, ging es genauso. Quelle: Buzzfeednews
McKernan, Ortiz und Andersen kontaktieren daraufhin die o.g. Anwälte um eine Sammelklage gegen die „KI-Bild-Generatoren“ einzureichen (betroffen: Stability AI, DeviantArt und Midjourney wegen der Nutzung von Stable Diffusion). „Wenn Produkte und Dienstleistungen, die auf generativen KI-Produkten basieren, betrieben werden dürfen, ist das absehbare Ergebnis, dass sie genau die Künstler ersetzen werden, deren gestohlene Werke diese KI-Produkte antreiben und mit denen sie konkurrieren“, heißt es in einer Pressemitteilung von Saveri.
Im Februar 2023 reichte der Stock-Image-Anbieter Getty Images in London eine eigene Klage gegen Stability AI ein und behauptet das Unternehmen habe „Millionen urheberrechtlich geschützte Bilder und die zugehörigen Metadaten rechtswidrig kopiert und verarbeitet“ um sein KI-Modell zu trainieren.
Im April 2023 versucht ein Fotograf seine Bilder aus einem Datensatz löschen zu lassen und scheiterte.
Quelle: vice.com
Dass der jährliche Kunstwettbewerb der Colorado State Fair für aufstrebende Digitalkünstler ein blaues Band an einen Teilnehmer verliehen hatte, der sein Wert mit Midjourney erstellt hatte, heizte die Diskussion noch zusätzlich an. Quelle:
Nicht alle in der Kunstszene sind der gleichen Meinung
Aber nicht alle sind der gleichen Meinung: „Wenn der Algorithmus Muster aus Bildern ausliest und diese verwendet, ist es im engen Sinn keine Kopie und somit keine Vervielfältigung“, meinen Gegner.
2016 lehnte der Oberste Gerichtshof der USA es ab, über eine Berufung von Autoren zu urteilen, die verhindern wollten, dass Google mehr als 20 Millionen urheberrechtlich geschützte Bücher scannt und für seine Google-Books-Website indexiert. Damit gilt die Entscheidung der Vorinstanz, die Google Recht gab: Das US-amerikanische Urheberrecht besagt, dass das Scrapen von Bildern oder anderen Inhalten für Trainingsdatensätze als „faire Verwendung“ gilt. Quelle: Süddeutsche Zeitung




