
Mithilfe des Monitoring Tools TRIN[IT]Y Probleme erkennen und in einer Oberfläche analysieren. Wir zeigen Ihnen 10 alltägliche Infrastrukturprobleme, die jeder IT-Admin kennt und die mit dem Monitoring Tool TRIN[IT]Y kontinuierlich überwacht werden. So stellen Sie die bestmögliche Nutzererfahrung für Ihre Kunden sicher.
10 alltägliche Infrastrukturprobleme, die jeder IT-Admin kennt und mithilfe des TRIN[IT]Y Monitoring Tools in einer Oberfläche analysieren kann
Jeder IT-Systemadministrator eines Unternehmens kennt das Problem: jede Komponente und zusätzlich jede Marke hat ihre eigene Software mit der ein entsprechend kleiner Teilbereich analysiert werden kann. Das erfordert viel Einarbeitungszeit in jedes einzelne Tool, unterschiedliche Zugangsdaten, sowie enormen Aufwand zum Vergleichen der ausgewiesenen Daten in deren unterschiedlichen Einheiten. Erschwerend kommt hinzu, dass die unterschiedlichen Tools in größeren Unternehmen oft in verschiedenen Organisationseinheiten zu finden sind (Storage, Server, Netzwerk, Applikation). Eine rasche Problemanalyse und professionelle Überwachung ist daher nicht einfach möglich für das Unternehmen.
Mithilfe des TRIN[IT]Y Monitoring Tools und seinen vielfältigen Funktionen ist das professionelle Überwachen der IT-Landschaft unkompliziert: Dieses Monitoring Tool greift Daten aus den unterschiedlichen Monitoring Tools der Komponenten ab und stellt diese zu einer E2E-Betrachtung zur Verfügung. Vom Server bis zur Applikation und das für IBM i, Linux oder AIX. Das ermöglicht Ihnen eine effektive Fehleranalyse in Ihrem Alltag und im Krisenfall (siehe auch Blogbeitrag zum Thema BCM) und unterstützt Sie im Management Ihrer vielfältigen Tätigkeiten. Dazu wollen wir Ihnen heute 10 übliche Problemfälle vorstellen, und wie Sie diese mit dem TRIN[IT]Y Monitoring Tool analysieren und überwachen können:
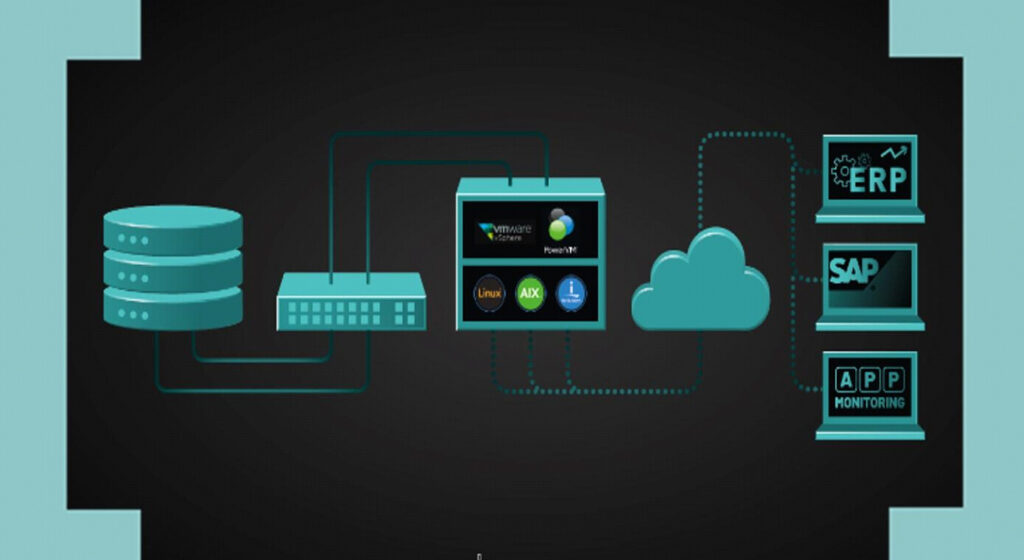
1. Die CPU Utilization Überwachung durch das Monitoring Tool
Der Klassiker unter den Useranfragen: „Warum ist das System so langsam“? Nur leider gibt es nicht nur „ein System“ im Unternehmen das langsam sein kann. Mehrere Komponenten wie Netzwerk, Storage und Server können die Ursache sein.
Einfache Steuerung des Tools via Dashboard
Navigieren Sie per Mausklick im Dashboard der TRIN[IT]Y Software direkt zur ersten Grafik und sehen Sie auf einen Blick wieviel Cores Ihres Servers verbraucht werden:
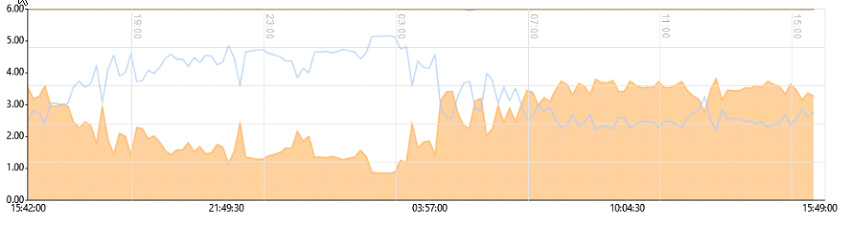
Innerhalb eines Monitoring Tools zu den Details wechseln
Sie wollen wissen welche LPAR welchen Anteil verbraucht? Auch das ist kein Problem: TRIN[IT]Y Monitoring Tool zeigt Ihnen auf einen Blick die Details zum ausgewählten Prozessor Pool. In der folgenden Darstellung ist gut zu erkennen, dass LPAR2 und LPAR3 den Großteil der CPU Kapazität verbrauchen.
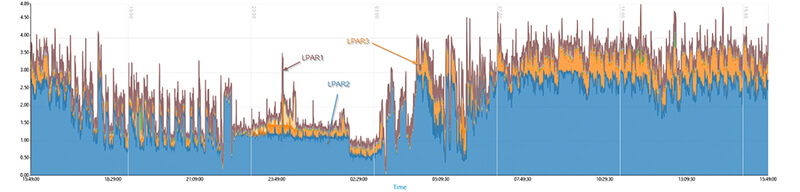
Ein Monitoring Tool für alle Ansichten und Details
Eine Frage bleibt allerdings offen – ist nun die CPU der einzelnen LPAR auch wirklich zu 100% ausgelastet und daher auf Anschlag? Dazu kurz auf die Detaildaten der LPAR gewechselt und man sieht die gewünschten Informationen:
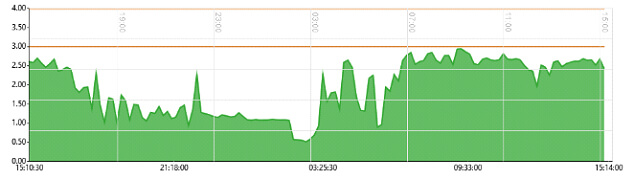
Die LPAR ist auf 3 Processing Units fixiert. Somit besteht hier kein Handlungsbedarf.
Anders sieht es bei der folgenden Maschine aus: hier reicht die CPU nicht mehr aus, um die Erfordernisse zu erfüllen:
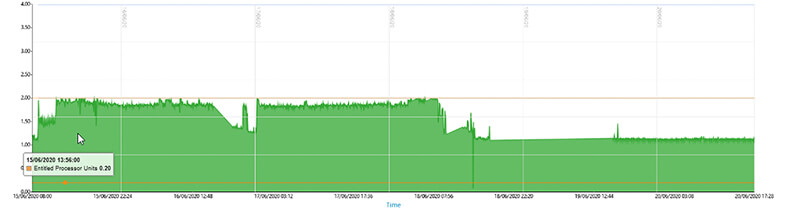
Ein Monitoring Tool mit schnellem Zugriff auf historische Daten
Aber auch viele andere Daten werden historisch aufgezeichnet und helfen somit einen Überblick über die Umgebung zu erhalten. Meist geht der Performance Verlust schleichend vor sich und der erste Zeitpunkt der Verschlechterung ist nicht bekannt. Durch das Monitoring Tool können historische Daten dabei helfen, mögliche Zeitpunkte und Ursachen ausfindig zu machen. Das schafft unsere Monitoring Software durch die InfluxDB. Damit unterstützt sie Sie nicht nur im Bereich der Überwachung, sondern auch beim Darstellen und Erklären des Problems beim Management Ihres Unternehmens.
2. Affinity Score Überwachung durch flexibles Monitoring
Bei Enterprise Systemen kommt es öfters vor, dass CPU und Memory über mehrere Systemeinheiten verteilt liegen. Dabei ist es für einen guten Affinity Score enorm wichtig, dass CPU und Memory einer einzelnen LPAR möglichst im gleichen Drawer/CEC liegen. Ist das nicht der Fall, fällt der Affinity Score. Ein manuell ausgeführtes Re-Arrangement von Performance zu Memory kann hier schon zu einer drastischen Performance Verbesserung und zu einer Verbesserung des Scores führen. Aber ist der Affinity Score meiner Systeme schlecht? Auch das finden Sie sehr einfach mit dem TRIN[IT]Y Monitoring Tool heraus:
3. Einlesen von Wait-time-accounting Daten innerhalb eines zentralen Monitoring Tools
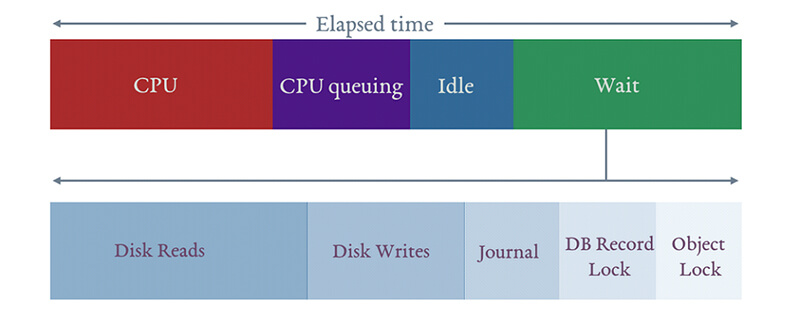
Ein Problem, das Sie bestimmt auch kennen: Sie wissen, dass das System langsam ist, weil die CPU im wait-Status ist und benötigen jetzt die Information, worauf es wartet.
Die IBM i hat hierzu das patentierte „Wait time accounting“. Dieses zeigt an, ob Threads auf der IBM i überhaupt warten müssen, und gegebenenfalls worauf sie warten. Somit ist es möglich Bottlenecks auf der IBM i oder externen Ressourcen eines Netzwerks ausfindig zu machen und die Applikation/LPAR/Storage so anzupassen, dass diese Bottlenecks nicht mehr bestehen.
Wenn ein Threat im Wait-Status ist, kann es mehrere Gründe dafür geben:
⦁ Ready to run / CPU queuing:
Dies ist ein spezieller Wartezustand und wird allgemein als „CPU Queuing“ bezeichnet. Dies bedeutet, dass der Thread oder die Task in die Warteschlange gestellt wird und darauf wartet, auf der CPU ausgeführt zu werden. Es gibt verschiedene Gründe, warum CPU-Warteschlangen auftreten können. Ein Beispiel könnte sein, wenn die Partition überlastet ist und es mehr Arbeit gibt, als die Partition aufnehmen kann. Dann kann die Arbeit in die Warteschlange gestellt werden, um auf die CPU zu warten. Dies kann mit einer Autobahn mit Rampenzählern verglichen werden; wenn die Autobahn überlastet ist, haben die Rampenzähler ein rotes Signal, sodass die Autos anhalten und warten müssen, bevor sie in den Verkehr einfahren können. Logische Partitionierung und gleichzeitiges Multithreading können auch zu CPU-Warteschlangen führen.
⦁ Idle wait:
Leerlaufwartezeiten sind eine normale und erwartete Bedingung. Leerlaufwartezeiten treten auf, wenn der Thread auf externe Eingaben wartet. Diese Eingabe kann von einem Benutzer, dem Netzwerk oder einer anderen Anwendung kommen. Bis diese Eingabe empfangen wird, gibt es keine Arbeit zu tun.
⦁ Blocked wait:
Blockierte Wartezeiten sind das Ergebnis von Serialisierungsmechanismen, um den Zugriff auf gemeinsam genutzte Ressourcen zu synchronisieren. Blockierte Wartezeiten können normal und zu erwarten sein. Beispiele hierfür sind der serialisierte Zugriff zum Aktualisieren einer Zeile in einer Tabelle, Platten-I/O-Operationen oder Kommunikations-I/O-Operationen. Blockierte Wartezeiten sind jedoch möglicherweise nicht normal, und es sind diese unerwarteten Blockierungspunkte, die Situationen darstellen, in denen die Wartezurechnung verwendet werden kann, um die Wartebedingungen zu analysieren.
Lesen Sie mehr dazu auf der IBM Website
Das TRIN[IT]Y Performance Monitoring Tool hilft hier schnell und ohne viel Vorwissen zu erkennen, woher die Waits kommen, ob die Applikation gut läuft, oder wo es Ansatzpunkte gibt die Performance zu verbessern. Auch Applikationsänderungen können schnell auf ihre Effektivität überprüft werden.
Im unteren Beispiel sieht man beispielsweise auf einen Blick, dass die CPU größtenteils durch Journal Locks ausgebremst wird:
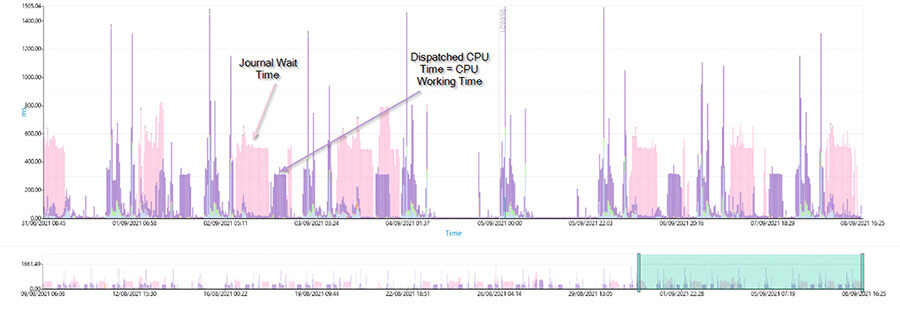
In der folgenden Grafik ist hingegen sofort erkennbar, dass die Threads kaum warten müssen – ein Beispiel einer gut laufenden Software:
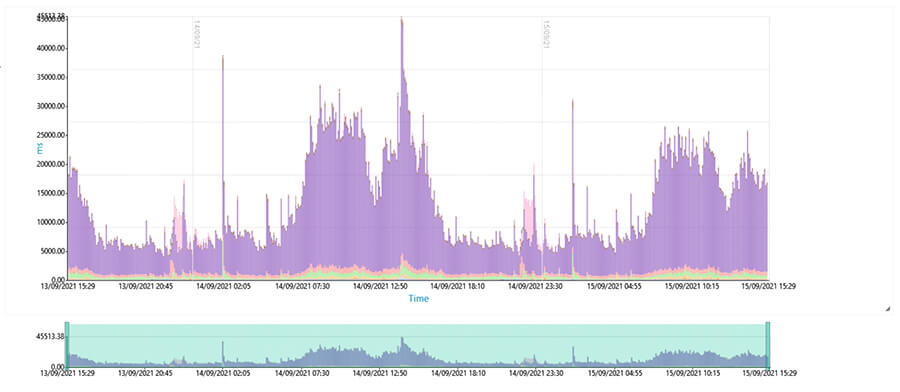
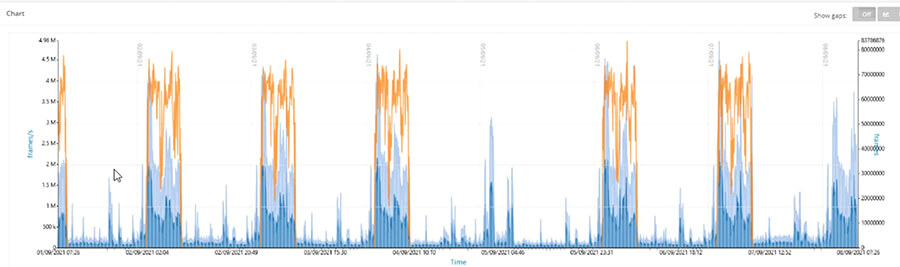
4. SAN Port Auslastung im ganzheitlichen TRIN[IT]Y Monitoring Tool
Mit der TRIN[IT]Y Software können Sie sich die Auslastung einzelner SAN Ports anzeigen lassen. In diesem Beispiel ist erkennbar, dass der Port durchgängig über einen langen Zeitraum immer mit 800MB/s schreibt. Mit dem Wissen, dass es sich hier um ein 8Gb Port handelt, wird schnell klar, dass die Auslastung am oberen Ende der Skala ist und dringend reagiert werden sollte. So geht professionelles Management mithilfe der richtigen Tools!
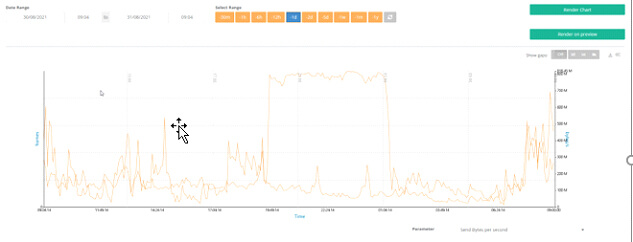
5. TRIN[IT]Y Monitoring Tool inklusive grafischer Nachverfolgung
Apropos „Mit dem Wissen, dass es sich hier um ein 8Gb Port handelt…“: Das TRIN[IT]Y Monitoring Tool zeigt Ihnen auch grafisch Ihre komplette Netzwerkkonfiguration der SAN Topologie mithilfe des Network Views an: vom Server, den virtuellen Fibre Channel Verbindungen des jeweiligen Client Systems, vom VIO Server sowie zusätzlich den physischen Kabelverbindungen vom VIO Server bis zum Fibre Channel Switch und deren Verbindungen zu Tape Laufwerken und Storage Systemen. Auch hier haben Sie die Möglichkeit mit der Maus einfach Details anzeigen zu lassen um Ihre Überwachung so effizient wie möglich zu halten.
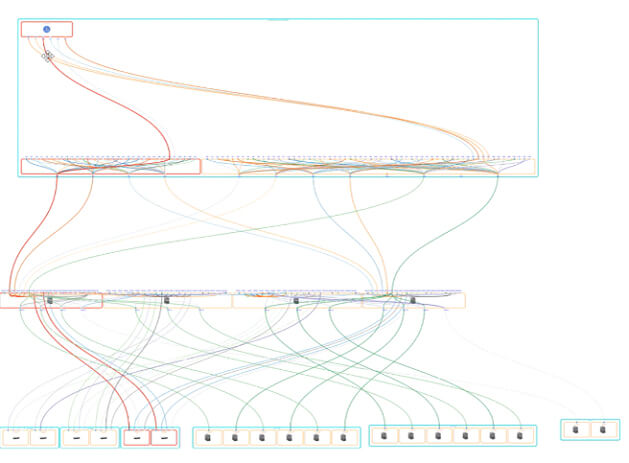
Diese View hilft Ihnen ebenfalls wenn Sie eine Konfiguration überprüfen müssen, da sie in Echtzeit direkt aus den Systemen Ihres Unternehmens abgeleitet wird.
6. Buffer credit zero Problem und dessen Monitoring
Das Problem mit herkömmlichen Monitoring Tools
Ein häufig auftretender Fall ist der „Slow drain Bottleneck“. In Zeiten der klassischen HDD war der Datenstau oft sehr schnell verifizierbar. Mit der Entwicklung der Hybrid und All-Flash Storage Systeme, sowie der immer größeren Komplexität der SAN’s, hat sich diese Möglichkeit jedoch verlagert und ist nicht mehr so einfach zu erkennen. Um das Problem zu verstehen, muss man die Ursache kennen:
Datenpakete werden von einem Sender (zB Server) über fibre channel (FC) Switches an einen Empfänger (zB Storage) gesendet. Dieser Datenverkehr zwischen zwei Komponenten wird über Puffer gesteuert. Für jeden Datenpaketblock den der FC Switch erhält (siehe Bild) reduziert sich die verfügbare Pufferkapazität, bzw. erhöht sich wieder für jedes Datenpaket das fertig verarbeitet und weitergesendet wurde. Die Kommunikation zum „Vorgänger“ bzw. „Nachfolger“ erfolgt via R_RDY (receive-ready) messages. Erst wenn der Sender die Information hat, dass ein Paket verarbeitet wurde und wieder Pufferkapazität zur Verfügung steht, kann das nächste Paket versendet werden. Ist diese Kapazität jedoch ausgeschöpft entsteht ein „Buffer Credit Zero“ und somit ein Backlog bei der Vorgängerkomponente. Jetzt gilt es herauszufinden wo genau das Problem liegt. Mit vielen Performance Monitoren können sie auslesen, dass der Server den Backlog hat und der Storage auf Input wartet. Aber ob nun der FC Switch 1 oder 2 das Problem ist, erkennen Sie daraus nicht.
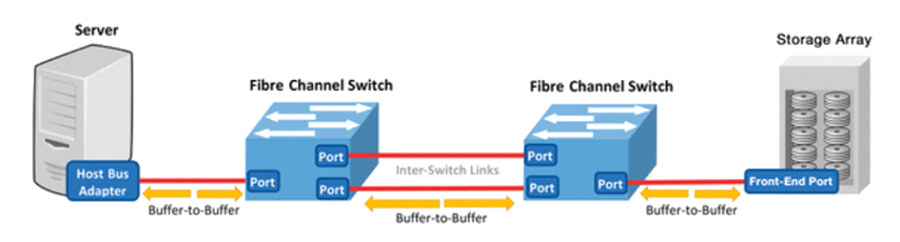
Die Lösung: TRIN[IT]Y Monitoring Tool
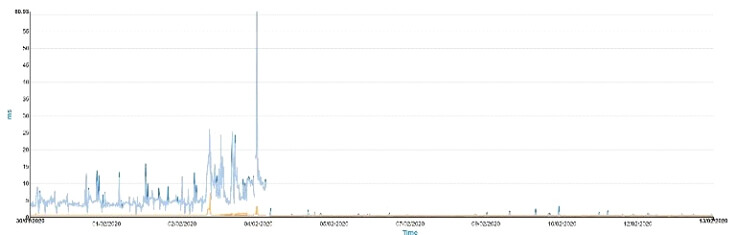
Mit dem TRIN[IT]Y Monitoring Tool können Sie das jedoch mit Grafiken schön erkennen. In dieser TRIN[IT]Y Grafik sehen Sie eine klassische IO Performance einer bestimmten SAN Komponente, die genau anzeigt, dass diese eine hohe Anzahl verzögerter Pakete hat. Mit der Erweiterung der Buffers am ISL und einiger Rekonfigurationen konnte die Performance im SAN wieder erhöht werden:
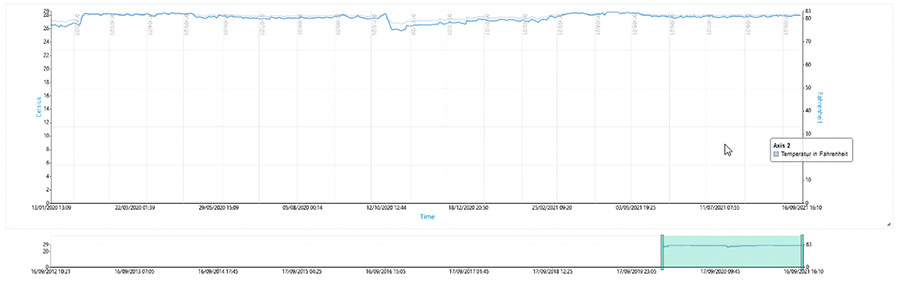
7. Temperaturkontrolle durch zuverlässiges Monitoring
Jeder Systemadministrator hat wohl auch schon die Erfahrung gemacht, dass sich ein System plötzlich wegen zu hohen Temperaturanstieges herunterfährt. Das ist auf der einen Seite, der immer stärker werdenden Hardware zu schulden, als auch durch immer höherer Packungsdichte der Racks. Auch hier hat jeder Hersteller und jeder Server, Switch und Storage sein eigenes Warnsystem, das auf die standardhinterlegte Spezifizationswerte individuell warnt. Auch hier hilft Ihnen das TRIN[IT]Y Monitoring Tool durch eine gesamtheitliche Darstellung über Ihre komplette IT-Landschaft.
8. Automatische Dokumentation der Konfiguration durch ein verlässliches Monitoring Tool
Die unbeliebteste Arbeit von IT-Administratoren ist wohl mit Sicherheit die Dokumentation. Nach Änderungen ist diese vor allem wichtig, um zu einem späteren Zeitpunkt Änderungen und eventuelle Differenzen verifizieren zu können. Eine der üblichen Tätigkeiten, die gerne verschoben wird, weil es immer höher priore Arbeiten im Unternehmen gibt. Und dann passiert es: Das System muss wieder hergestellt werden und es fehlt der Letztstand der Konfiguration sowie Detailinformationen zur Wiederherstellung. Auch da hilft Ihnen das TRIN[IT]Y Monitoring Tool durch seine automatische Dokumentationsmöglichkeit:
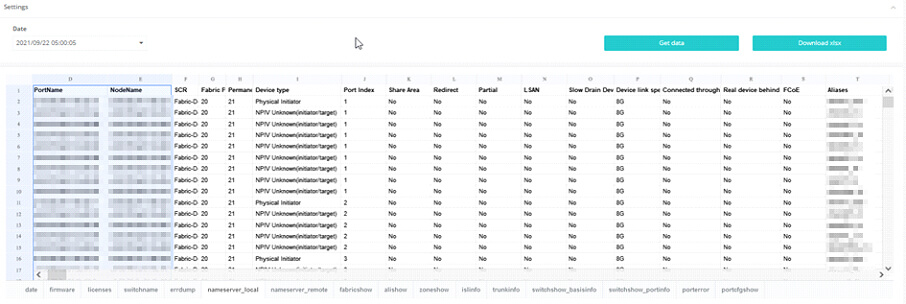
Überlassen Sie unserem Monitoring Tool die Dokumentation
Die Dokumentation können Sie je nach Ihren gewünschten Intervallen automatisch abgezogen und im Excel Formaten abgespeichert werden. Damit verlieren Sie, dank dem TRIN[IT]Y Monitoring Tool, nie wieder aktuelle Informationen. Konzentrieren Sie sich auf aktuelle Themen des Alltags und verlassen Sie sich darauf alle notwendigen Daten zur Verfügung zu haben, wenn Sie sie im Notfall für Rekonstruktionen benötigen.
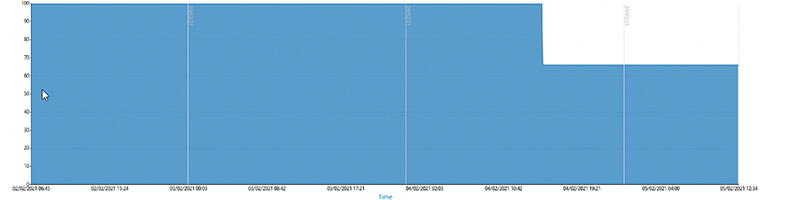
9. Migrationsplanung und -erfolgsbeweis mithilfe eines konstanten Monitorings
Mit den bereits erwähnten Funktionen haben Sie alle Werkzeuge, Berichte und Belege in der Hand, um das Management Ihres Unternehmens davon zu überzeugen, dass es an der Zeit für IT Investitionen ist. Allerdings haben Sie mit diesem Performance Monitoring auch die Möglichkeit Ihrem Management zu belegen, dass die neue Anschaffung auch sinnvoll war; beispielsweise mit einer Auslastungsgrafik. In diesem Fall ist klar ersichtlich, dass die Migration ein eindeutiger Erfolg war; Ihre Überwachung hat das bewiesen.
10. Individualanpassungen in einem flexiblen und gleichzeitig beständigen Monitoring Tools
Sie haben auch noch andere Anforderungen? Mit dem TRIN[IT]Y Monitoring Tool sind Sie flexibel wie noch nie: Wir können z.B. mit wenig Aufwand Ihre performance-relevanten Applikationsdaten in die Gesamtanwendung integrieren. So ist es beispielsweise möglich die Antwortzeit von Web-Anwendungen mit der Auslastung am Backend System zu verknüpfen, oder die Anzahl der Kundenanfragen mit der I/O Auslastung am externen Speicher miteinander zu verbinden, und vieles mehr. TRIN[IT]Y Monitoring Tool wird stetig weiterentwickelt und Kundenwünsche und -anforderungen werden dabei mitberücksichtigt, weil wir Ihnen ein zuverlässiges Performance Management Tool zur Verfügung stellen wollen.
Wie Sie gesehen hat TRIN[IT]Y Monitoring Tool viele Vorteile die Sie so in Kombination noch nicht kennen. Selbstverständlich gibt es auch folgende unerlässliche Funktionen:
⦁ Individuell anpassbares Dashboard
⦁ 5 Metriken in einer Grafik darstellbar, unabhängig von Einheiten, Daten oder Komponente
⦁ Vergleich zweier Zeiträume in einer Darstellung
⦁ Userverwaltung/Zugriffsberechtigungen
⦁ Smart Alerting
⦁ Managementberichte
⦁ Mehrsprachigkeit
⦁ Daten aus jahrelanger Historie pfeilschnell, immer verfügbar
⦁ Und vieles mehr (agentless, InfluxDB, etc)




